Performance
To evaluate the performance benefits Polly currently provides we compiled the Polybench 2.0 benchmark suite. Each benchmark was run with double precision floating point values on an Intel Core Xeon X5670 CPU @ 2.93GHz (12 cores, 24 thread) system. We used PoCC and the included Pluto transformations to optimize the code. The source code of Polly and LLVM/clang was checked out on 25/03/2011.
The results shown were created fully automatically without manual interaction. We did not yet spend any time to tune the results. Hence further improvements may be achieved by tuning the code generated by Polly, the heuristics used by Pluto or by investigating if more code could be optimized. As Pluto was never used at such a low level, its heuristics are probably far from perfect. Another area where we expect larger performance improvements is the SIMD vector code generation. At the moment, it rarely yields to performance improvements, as we did not yet include vectorization in our heuristics. By changing this we should be able to significantly increase the number of test cases that show improvements.
The polybench test suite contains computation kernels from linear algebra routines, stencil computations, image processing and data mining. Polly recognizes the majority of them and is able to show good speedup. However, to show similar speedup on larger examples like the SPEC CPU benchmarks Polly still misses support for integer casts, variable-sized multi-dimensional arrays and probably several other constructs. This support is necessary as such constructs appear in larger programs, but not in our limited test suite.
Sequential runs
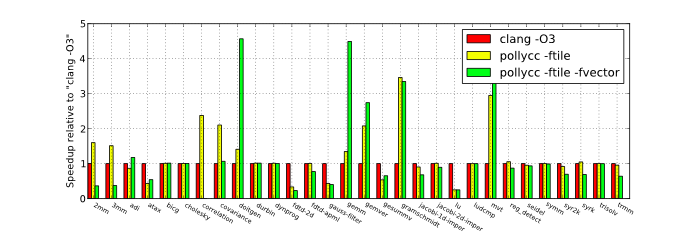
For the sequential runs we used Polly to create a program structure that is optimized for data-locality. One of the major optimizations performed is tiling. The speedups shown are without the use of any multi-core parallelism. No additional hardware is used, but the single available core is used more efficiently.Small data size
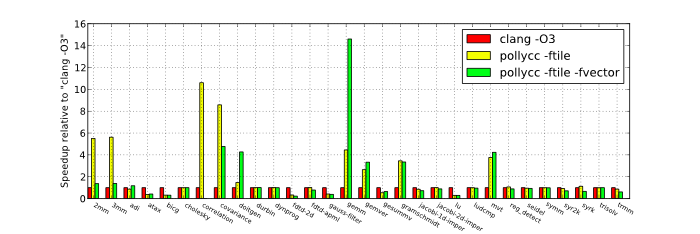
Large data size
Parallel runs
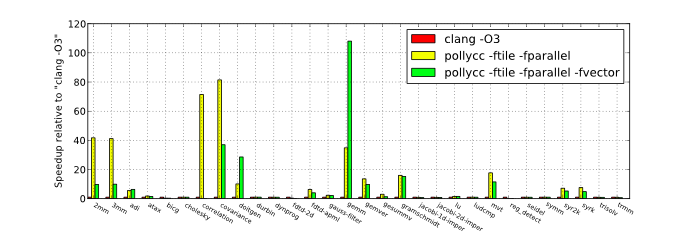
For the parallel runs we used Polly to expose parallelism and to add calls to an OpenMP runtime library. With OpenMP we can use all 12 hardware cores instead of the single core that was used before. We can see that in several cases we obtain more than linear speedup. This additional speedup is due to improved data-locality.Small data size
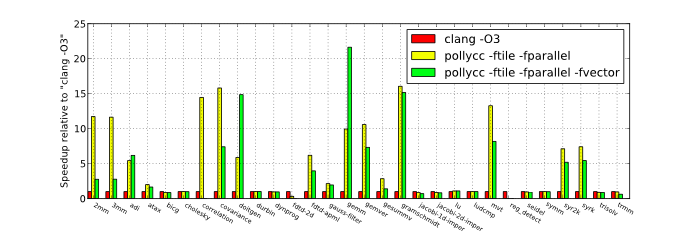
Large data size